
| 중위 표기법 | 후위 표기법 |
| 1 + 3 | 1 3 + |
| 23 / 7 + 12 | 23 7 / 12 + |
| (117.32 + 83) * 49 | 117.32 83 + 49 * |
| 1 - 3 * 2 | 1 3 2 * - |
우리 일상적으로 사용하는 계산식을 중위 표기법(Infix Notation)이라 부른다.
이 방법은 사람이 보면 바로 계산이 가능하지만 컴퓨터가 보기엔 계산이 힘들다. 그래서 컴퓨터가 비교적 쉽게 받아 들일 수 있는 표기법이 없을까 하고 나온게 후위 표기법이다.
그럼 후위 표기법(Postfix Notation)이란 무엇일까?
후위 표기법은 역 폴리쉬 표기법이라고도 하는데 이 표기법의 규칙은 연산자를 피연산자 뒤에 위치시키는 것이다.
그래서 계산을 후위표기식으로 한다면 계산식을 쉽게 이해가능하다.
후위 표기식을 계산하는 알고리즘
후위 표기식을 계산하는 알고리즘은 두 가지 규칙으로 이루어져 있다. 23 7 / 12 + (23 / 7 + 12)를 예로 들어보겠다
첫번째 규칙은 식은 왼쪽부터 요소를 읽어내면서 피연산자는 스택에 담는다 이다
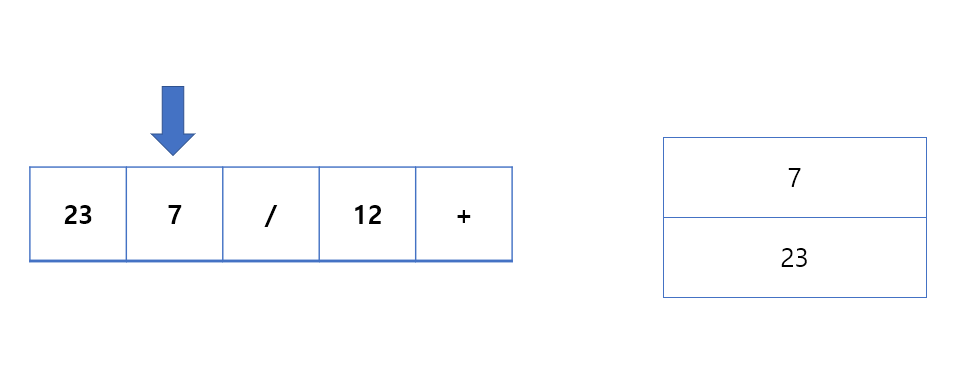
위 그림처럼 피연산자는 스택에 담으며 순회한다.
연산자를 만나면 두 번째 규칙인 스택에서 피연산자 2개를 꺼내 연산을 수행하고, 그 연산 결과를 다시 스택에 삽입 을 따른다.
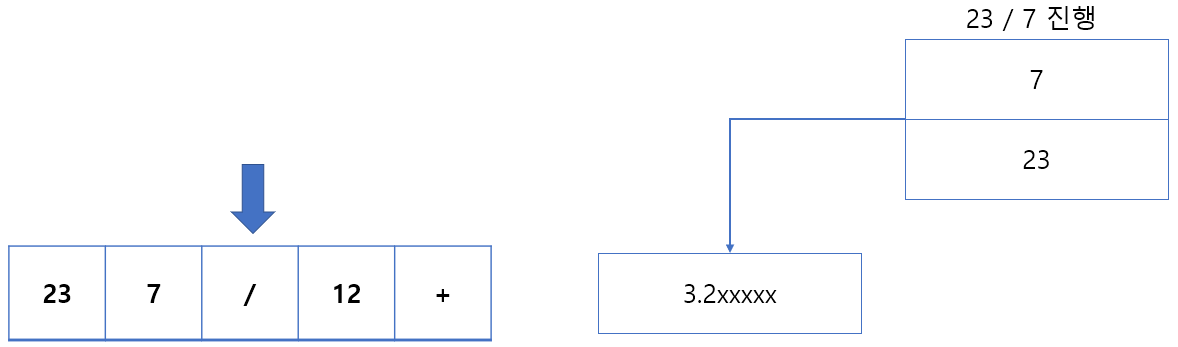
이 규칙에 따라 계속 진행하면 결국 계산의 최종 값에 스택에 남아있게 되는것입니다.
중위 표기법에서 후위 표기법으로의 변환 알고리즘
우리는 이제 후위 표기법이 무엇인지 알고 후위 표기법을 컴퓨터가 어떻게 계산하는지 알고 있다.
남은것은 중위 표기법은 후위 표기법으로 바꾸는 것이다.
아래 과정은 다익스트라가 고안한 알고리즘이다.
- 입력받은 중위 표기식에서 토큰을 읽는다.
- 토큰이 피연산자이면 토큰을 결과에 출력한다.
- 토큰이 연산자(괄호포함)인 경우, 스택의 최상위 노드에 담겨있는 연산자가 토큰보다 우선순위가 높은지 비교해 높다면 최상위 노드를 스택에서 꺼내 결과에 출력하며, 낮거나 스택이 비게되면 해당 작업을 중단한다. 작업 후에 토큰을 스택에 삽입한다.
- 토큰이 ')' 이면 최상위 노드에 '('가 올 때까지 스택에 제거 연산을 수행하고 제거한 노드에 담긴 연산자를 출력한다.
- 중위 표기식에 읽을 것이 없다면 빠져나가고 있다면 다시 1부터 반복한다.
이 알고리즘을 토대로 23 / 7 + 12 을 후위 표기식으로 변환해보겠다.
| 토큰 | 작업 | 출력 | 스택 |
| 23 | 23 출력 | 23 | |
| / | 스택에 '/' 삽입 | / | |
| 7 | 7 출력 | 23 7 | / |
| + | 스택에 '/' 가 '+' 보다 우선순위가 높으므로 스택에서 꺼내 출력한 후 +를 스택에 넣는다 | 23 7 / | + |
| 12 | 12 출력 | 23 7 / 12 | + |
| 모두 읽음. 스택 값 모두 pop | 23 7 / 12 + |
| 중위 표기법 | 후위 표기법 |
| 1 + 3 | 1 3 + |
| 23 / 7 + 12 | 23 7 / 12 + |
| (117.32 + 83) * 49 | 117.32 83 + 49 * |
| 1 - 3 * 2 | 1 3 2 * - |
우리 일상적으로 사용하는 계산식을 중위 표기법(Infix Notation)이라 부른다.
이 방법은 사람이 보면 바로 계산이 가능하지만 컴퓨터가 보기엔 계산이 힘들다. 그래서 컴퓨터가 비교적 쉽게 받아 들일 수 있는 표기법이 없을까 하고 나온게 후위 표기법이다.
그럼 후위 표기법(Postfix Notation)이란 무엇일까?
후위 표기법은 역 폴리쉬 표기법이라고도 하는데 이 표기법의 규칙은 연산자를 피연산자 뒤에 위치시키는 것이다.
그래서 계산을 후위표기식으로 한다면 계산식을 쉽게 이해가능하다.
후위 표기식을 계산하는 알고리즘
후위 표기식을 계산하는 알고리즘은 두 가지 규칙으로 이루어져 있다. 23 7 / 12 + (23 / 7 + 12)를 예로 들어보겠다
첫번째 규칙은 식은 왼쪽부터 요소를 읽어내면서 피연산자는 스택에 담는다 이다
위 그림처럼 피연산자는 스택에 담으며 순회한다.
연산자를 만나면 두 번째 규칙인 스택에서 피연산자 2개를 꺼내 연산을 수행하고, 그 연산 결과를 다시 스택에 삽입 을 따른다.
이 규칙에 따라 계속 진행하면 결국 계산의 최종 값에 스택에 남아있게 되는것입니다.
중위 표기법에서 후위 표기법으로의 변환 알고리즘
우리는 이제 후위 표기법이 무엇인지 알고 후위 표기법을 컴퓨터가 어떻게 계산하는지 알고 있다.
남은것은 중위 표기법은 후위 표기법으로 바꾸는 것이다.
아래 과정은 다익스트라가 고안한 알고리즘이다.
- 입력받은 중위 표기식에서 토큰을 읽는다.
- 토큰이 피연산자이면 토큰을 결과에 출력한다.
- 토큰이 연산자(괄호포함)인 경우, 스택의 최상위 노드에 담겨있는 연산자가 토큰보다 우선순위가 높은지 비교해 높다면 최상위 노드를 스택에서 꺼내 결과에 출력하며, 낮거나 스택이 비게되면 해당 작업을 중단한다. 작업 후에 토큰을 스택에 삽입한다.
- 토큰이 ')' 이면 최상위 노드에 '('가 올 때까지 스택에 제거 연산을 수행하고 제거한 노드에 담긴 연산자를 출력한다.
- 중위 표기식에 읽을 것이 없다면 빠져나가고 있다면 다시 1부터 반복한다.
이 알고리즘을 토대로 23 / 7 + 12 을 후위 표기식으로 변환해보겠다.
| 토큰 | 작업 | 출력 | 스택 |
| 23 | 23 출력 | 23 | |
| / | 스택에 '/' 삽입 | / | |
| 7 | 7 출력 | 23 7 | / |
| + | 스택에 '/' 가 '+' 보다 우선순위가 높으므로 스택에서 꺼내 출력한 후 +를 스택에 넣는다 | 23 7 / | + |
| 12 | 12 출력 | 23 7 / 12 | + |
| 모두 읽음. 스택 값 모두 pop | 23 7 / 12 + |