
라우터는 3 계층에서 동작하고 이름처럼 경로를 지정해주는 장비이다.
라우터에 들어오는 패킷의 목적지 IP 주소를 확인하고 자신이 가진 경로 정보를 이용해 패킷의 최적의 경로로 포워딩한다.
또한 원격지 네트워크와 연결할 때 필수 네트워크 장비이며 네트워크를 구성하는 핵심 장비이다.
라우터의 동작 방식과 역할
라우터는 다양한 경로 정보를 수집해 최적의 경로를 라우팅 테이블에 저장한 후 패킷이 라우터로 들어오면 도착지 IP 주소와 라우팅 테이블을 비교해 최선의 경로로 패킷을 내보낸다. 이 말은 패킷의 목적지 주소가 라우팅 테이블에 없다면 패킷을 버린다는 것이다.
패킷 포워딩 과정에서 기존 2 계층 헤더 정보를 제거한 후 새로운 2 계층 헤더를 만든다.
이제부터 라우터의 동작방식인 경로 지정, 브로드캐스트 컨트롤, 프로토콜 변환 알아보자.
경로 지정
라우터는 도착지의 IP 주소를 확인하는데 IP주소는 네트워크 주소와 호스트 주소로 나뉜 계층 구조를 기반으로 설계되어 로컬 네트워크와 원격지 네트워크를 구분할 수 있고 네트워크 주소를 기반으로 경로를 찾을 수 있기 때문에 IP주소를 확인한다.
IP 주소란
IP 주소 2 계층의 물리 주소인 MAC 주소와 달리 IP 주소는 3 계층의 논리 주소를 사용한다. 대부분의 네트워크가 TCP/IP로 동작하므로 IP 주소체계를 이해하는 것이 네트워크 이해에 매주 중요하다. IP
rooftoproom-whale.tistory.com
그래서 라우터는 원격지에 있는 적절한 경로로 패킷을 포워딩할 수 있으며 이러한 역할을 2 가지로 구분해 수행한다.
경로 정보를 얻는 역할과 얻은 경로 정보를 확인하고 패킷을 포워딩하는 역할이다.
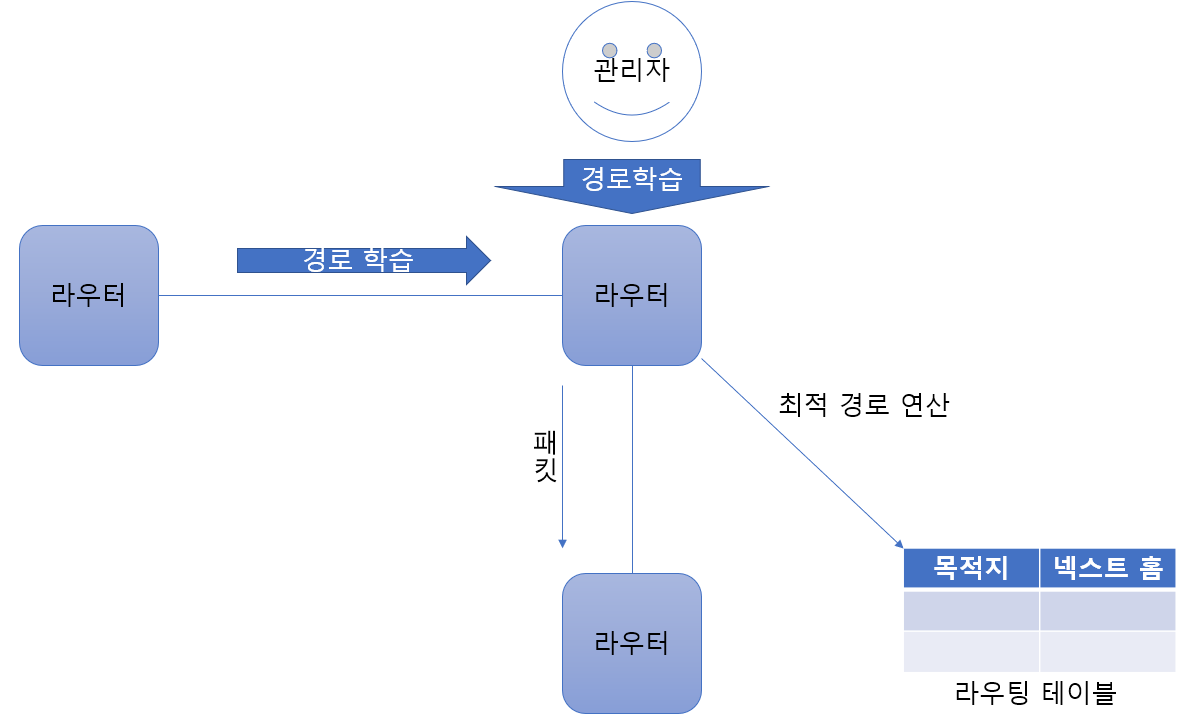
다양한 방법으로 경로 정보를 얻을 수 있는데 총 3 가지의 방법이 있다.
- IP 주소를 입력하면 자연스럽게 인접 네트워크 정보를 얻는 방법
- 관리자가 직접 경로 정보를 입력하는 방법
- 라우터끼리 서로 경로 정보를 자동으로 교환하는 방법
브로드캐스트 컨트롤(Broadcast Control)
스위치는 패킷의 도착지 주소를 모르면 어딘가에 존재할지 모를 장비와의 통신을 위해 플러딩해 패킷을 모든 포트로 전송한다. LAN 어딘가에 도착지가 있다고 가정하고 보내기 때문에 쓸모없는 패킷이 전송되어 전체 네트워크에 무리가 갈 수 있다고 생각할 수 있지만 LAN은 크기가 작고 도착지 NIC에서 자신의 주소와 패킷의 주소가 다르면 패킷을 버리기 때문에 플러딩이 네트워크에 큰 무리는 주지 않는다.
반면 라우터는 패킷을 원격지로 보내는 것이 목표이기때문에 3 계층에서 동작하고 도착지가 명확할 때만 통신을 허락한다.
만약 스위치처럼 동작한다면 목적지가 다르거나 명확하지 않은 패킷이 플러딩되어 인터넷에 이러한 패킷이 가득 차 통신 불능 상태가 될 수 있다.
라우터는 바로 연결되어 있는 네트워크 정보를 제외하고 경로 습득 설정을 하지 않으면 패킷을 포워딩할 수 없다.
라우터의 기본 동작은 멀티캐스트 정보를 습득하지 않고 브로드캐스트 패킷을 전달하지 않는다. 이 기능을 이용해 브로드캐스트가 다른 네트워크로 전파하는 것을 막을 수 있는데 이 기능을 브로드캐스트 컨트롤/멀티캐스트 컨트롤 이라고 한다.
그래서 브로드캐스트가 많이 발생한다면 라우터로 네트워크를 분리해 성능을 높일 수 있다.
프로토콜 변환
라우터의 또 다른 역할은 서로 다른 프로토콜로 구성된 네트워크를 연결하는 것이다.
현대에는 이더넷으로 수렴되므로 이 역할이 줄어들었지만 과거에는 LAN 프로토콜과 WAN 프로토콜이 전혀 달라 원격지 네트워크와 통신하려면 LAN 기술이 WAN 기술로 변환되어야만 가능했는데 이 역할을 라우터가 담당했다.
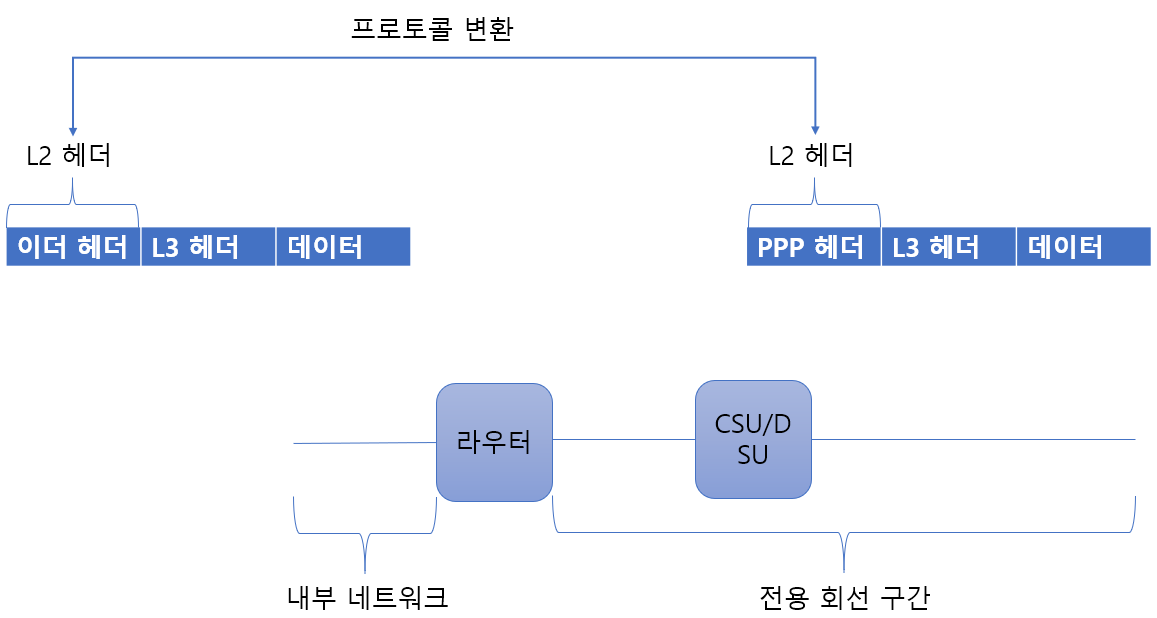
라우터에 패킷이 들어오면 2계층까지의 헤더 정보를 벗겨내고 3 계층 주소를 확인한 후 2 계층 헤더 정보를 새로 만들어 외부로 내보낸다. 그래서 라우터에 들어올 때와 나갈 때 헤더 정보가 다른 것이다.
이 기능을 이용하면 전혀 다른 기술 간 변환이 가능하다. 저속 전용회선에서 WAN 구간은 PPP와 같은 WAN 프로토콜이 사용되고 LAN 구간은 이더넷 프로토콜이 사용된다. LAN 구간에서 패킷이 라우터를 지나면서 2 계층까지의 헤더가 벗겨지고 WAN 구간으로 패킷이 나올 때 PPP 헤더로 변경되어 프로토콜이 변환된다.
경로 지정 - 라우팅/스위칭
라우터가 패킷을 처리할 때는 크게 두 가지 작업을 수행한다.
- 경로 정보를 얻어 경로 정보를 정리하는 역할
- 정리된 경로 정보를 기반으로 패킷을 포워딩하는 역할
라우터는 본인이 모르는 목적지를 가진 패킷을 버리기때문에 패킷이 들어오기 전 경로 정보를 충분히 수집하고 있어야한다.
클래스리스 네트워크로 전환된 후에는 같은 클래스에 있는 주소조차 서브네팅된 상태로 분산되어 존재하므로 경로 정보가 기존보다 훨씬 많아졌다. 그렇기 때문에 라우터는 많은 경로 정보를 얻어 최적의 경로 정보인 라우팅 테이블을 적절히 유지해야 한다.
라우터는 서브넷 단위로 라우팅 정보를 습득하고 라우팅 정보를 최적화하기 위해 서머리(Summary) 작업을 통해 여러 개의 서브넷 정보를 뭉쳐 전달한다. 그래서 패킷 목적지 주소와 라우팅 테이블 정보가 정확히 일치하지 않더라도 수많은 정보 중 목적지에 가장 근접한 정보를 찾아 패킷을 포워딩해야 한다.
라우팅 동작과 라우팅 테이블
현대 인터넷에서는 인접한 라우터까지만 경로를 지정하면 인접 라우터에서 최적의 경로를 다시 파악한 후 라우터로 패킷을 포워딩한다. 네트워크 한 단계씩 뛰어넘는다는 의미로 홉-바이-홉(Hop-by-Hop) 라우팅이라 부르고 인접한 라우터를 넥스트 홉(Next Hop)이라 부른다.
라우터는 패킷이 목적지로 가는 전체 경로를 파악하지 않고 최적의 넥스트 홉을 선택해 보내준다.

넥스트 홉을 지정할 때는 3 가지 방법을 사용할 수 있다.
- 다음 라우터의 IP를 지정하는 방법(넥스트 홉 IP 주소)
- 라우터의 나가는 인터페이스를 지정하는 방법
- 라우터의 나가는 인터페이스와 다음 라우터의 IP를 동시에 지정하는 방법
라우터에서 넥스트 홉을 지정할 때는 상대방 라우터의 인터페이스 IP 주소를 지정하는 방법을 사용한다.
상대방 넥스트 홉 라우터의 IP를 모르더라도 MAC 주소 정보를 알아낼 수 있을 때만 라우터의 나가는 인터페이스를 지정하는 방법을 쓸 수 있다. WAN 구간 전용선에서 PPP(Point-to-Point)나 HLDC(High Level Datalink Control)와 같은 프로토콜을 사용해 상대방의 MAC 주소를 알 필요가 없거나 상대방 라우터에서 프록시 ARP가 동작해 IP 주소를 모르더라도 상대방의 MAC 주소를 알 수 있을때와 같은 한정된 조건에서만 사용할 수 있다.
이런 경우는 특수한 경우이므로 상대방 IP 주소를 넥스트 홉으로 지정해야 한다.
인터페이스를 설정할 때 라우터의 나가는 물리 인터페이스를 지정하는 것이 일반적이지만 IP주소와 인터페이스를 동시에 사용할 때는 VLAN 인터페이스와 같은 논리적인 인터페이스를 사용할 수 있다.
PPP(Point-to-Point) : 두 통신 노드 간의 직접적인 연결을 위해 일반적으로 사용되는 데이터 링크 프로토콜
HLDC(High Level Datalink Control) : 컴퓨터가 일대일 혹은 일대다로 연결된 환경에 데이터의 송수신 기능을 제공
프록시 ARP : 한 호스트(일반적으로 라우터)가 다른 시스템에 대해 의도된 ARP 요청에 응답하는 기술
라우터 인터페이스 : 라우터의 접속 가능한 포트
라우터는 출발지와 상관없이 목적지 주소와 라우팅 테이블을 비교해 어느 경로로 포워딩할지 결정한다.
그래서 라우팅 테이블을 만들 때는 목적지 정보만 수집하고 패킷이 들어오면 목적지 주소를 확인해 패킷을 넥스트 홉으로 포워딩한다.
라우팅 테이블에 저장하는 데이터는 1. 목적지 주소, 2. 넥스트 홉 IP 주소, 나가는 로컬 인터페이스(선택 가능)이다.
라우터에는 패킷의 출발지 주소를 이용하는 PBR(Policy-Based Routing) 기능이 있지만 라우팅 테이블은 출발지 주소를 이용하지 않기 때문에 이 기능을 사용할 수 없다.
<참고> 루프가 없는(Loop Free) 3 계층 : TTL(Time To Live)
3 계층의 IP 헤더에는 패킷이 네트워크에 살아 있을 수 있는 시간을 제한하는 TTL이라는 필드가 있다.
인터넷 구간에 쓸모없는 패킷이 돌아다녀 대역폭을 낭비하는 것을 막기 위해 주소가 불분명한 것은 라우터가 버린다.
허나 이는 정상적으로 운영되던 사이트가 갑자기 없어질 수 있고 대안 경로를 찾다가 두 대의 라우터가 서로 마주 봐 루프가 생길 수 있다.
그래서 모든 패킷은 TTL이라는 수명 값을 가지고 있고 이 값이 0이 되면 네트워크 장비에서 버려진다.
이때 TTL의 Time은 실제 초와 같은 시간이 아니라 홉을 지칭하며 하나의 홉을 지날 시 1씩 줄어든다.
라우팅(라우터가 경로 정보를 얻는 방법)
경로 정보를 얻는 방법은 아래와 같이 총 3 가지가 있다.
- 다이렉트 커넥티드
- 스태틱 라우팅
- 다이나믹 라우팅
이 방법들을 통해 경로를 수집하고 목적지에 대한 최적의 경로를 선정해 라우팅 테이블을 만든다.
먼저 다이렉트 커넥티드에 대해 알아보자
다이렉트 커넥티드
IP주소를 입력할 때 사용된 IP 주소와 서브넷 마스크로 해당 IP 주소가 속한 네트워크 주소 정보를 알 수 있다.
라우터나 PC는 이 정보로 해당 네트워크에 대한 라우팅 테이블을 자동으로 만든다. 이 경로 정보를 다이렉트 커넥티드 라고 한다.
이 정보는 인터페이스에 IP를 설정하면 자동 생성되는 정보이므로 정보를 강제로 지울 수 없고 해당 네트워크 설정을 삭제하거나 해당 네트워크 인터페이스가 비활성화되어야만 자동으로 사라진다.
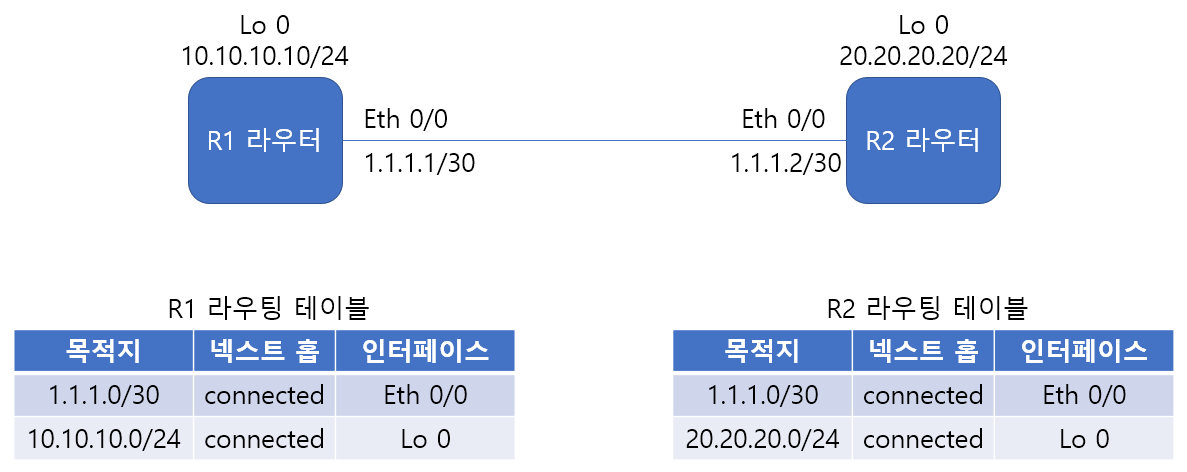
스태틱 라우팅
스태틱 라우팅은 정적, 말 그대로 관리자가 목적지 네트워크와 넥스트 홉을 직접 지정해 경로 정보를 입력하는 것이다.
다이렉트 커넥티드처럼 연결된 인터페이스 정보가 삭제, 비활성화되면 라우팅 정보가 자동 삭제된다.
허나 물리 인터페이스가 아닌 논리 인터페이스는 물리 인터페이스가 비활성화되더라도 라우팅 테이블에서 사라지지 않을 수 있다.
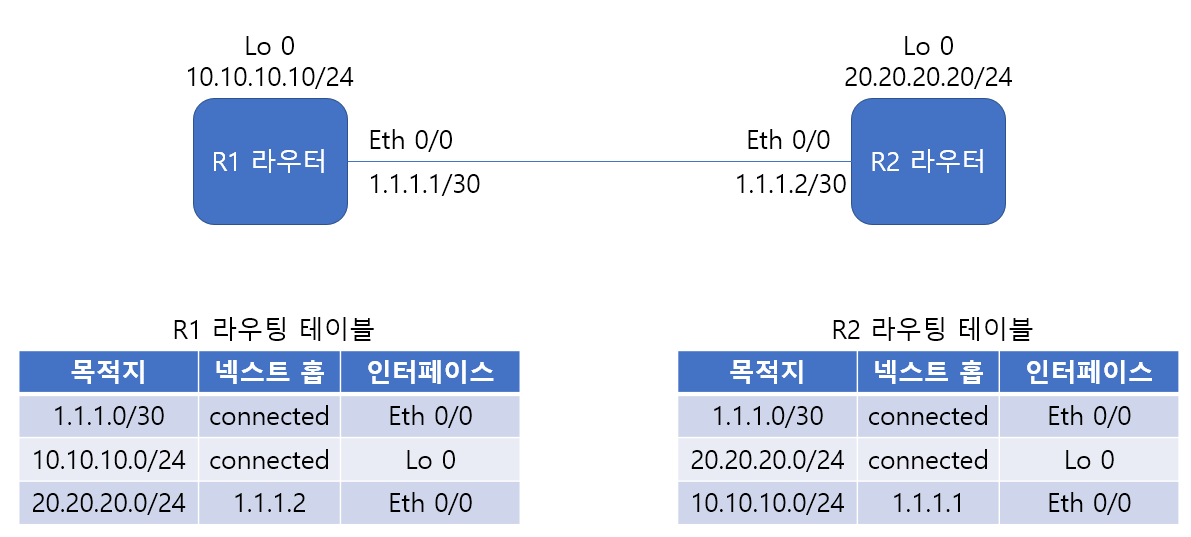
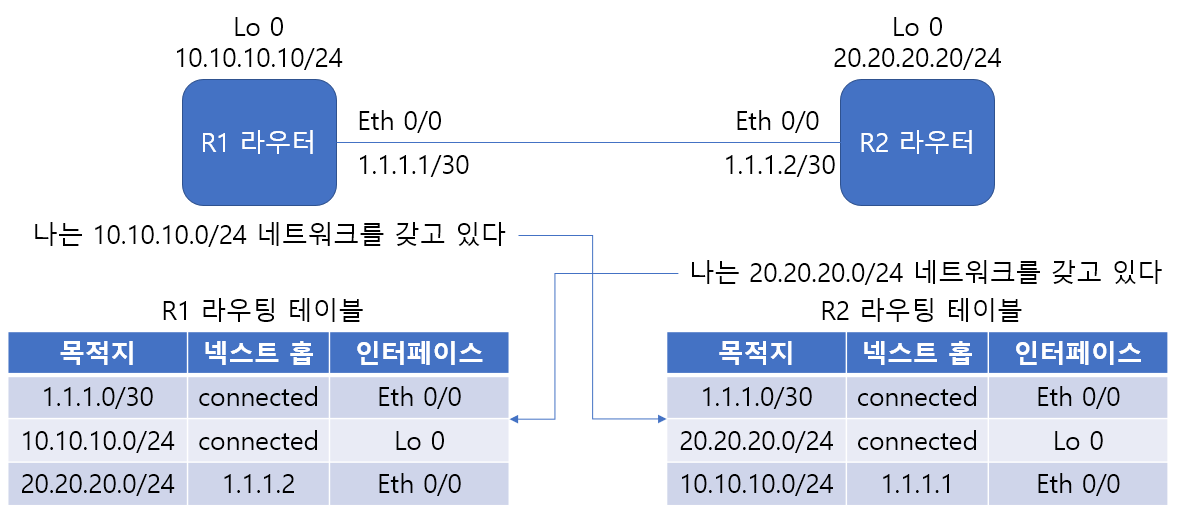
R1은 다이렉트 커넥티드 학습된 상태에서 20.20.20.20/24에 대한 네트워크 정보가 없다. R1의 10.10.10.0/24 네트워크가 R2의 20.20.20.20과 통신하려면 넥스트 홉을 1.1.1.2로 스태틱 라우팅을 설정해야 한다.
네트워크 통신은 양뱡향이기 때문에 이때 되돌아오는 패킷을 고려해야 한다. R2 또한 10.10.10.0/24 네트워크에 대한 정보가 없기 때문에 스태틱 라우팅을 통해 10.10.10.0/24 네트워크와 넥스트 홉 1.1.1.1을 추가한다.
다이나믹 라우팅
스태틱 라우팅은 변화가 적은 네트워크에서 손쉽게 관리할 수 있는 방법이지만 큰 네트워크에서는 관리에 무리가 있다.
이는 라우터 너머의 다른 라우터의 상태 정보를 파악할 수 없어 라우터 사이의 회선이나 라우터에 장애가 발생하면 장애 상황을 파악하고 대체 경로로 패킷을 보낼 수 없기 때문이다.
다이나믹 라우팅은 이런 스태틱 라우팅의 단점을 보완해준다. 라우터끼리 자신이 알고 있는 경로 정보나 링크 상태 정보를 교환해 전체 네트워크 정보를 학습한다. 주기적으로 또는 상태 정보가 변경될 때마다 정보 교환을 하기 때문에 장애가 발생한다면 대체 경로로 패킷을 포워딩할 수 있다.
이러한 점 덕분에 현재 대부분의 네트워크는 다이나믹 라우팅을 사용한다.
스위칭(라우터가 경로를 지정하는 방법)
스위칭이란 패킷이 들어와 라우팅 테이블을 참조하고 최적의 경로를 찾아 라우터 외부로 포워딩하는 작업을 말한다.
2계층의 스위치와 이름이 비슷하지만 라우터가 패킷 경로를 지정해 보내는 작업을 말한다.
패킷을 최선의 경로로 내보낼 때도 여러 가지를 고려해야 한다. 들어온 패킷의 목적지가 라우팅 테이블에 있는 정보와 완벽히 일치할 때도 있지만 비슷하게 일치하거나 일치하지 않는 경우도 생길 수 있기 때문이다.
라우팅 테이블에 일치하는 경로 정보가 없지만 가장 가까운 경로 정보를 매칭해주는데 이를 롱기스트 프리픽스 매치(Longest Prefix Match)라고 한다.
<참고>롱기스트 프리픽스 매치(Longest Prefix Match)
라우터가 패킷을 포워딩할 때 자신이 갖고 있는 라우팅 테이블에서 가장 좋은 항목을 찾는 알고리즘.
맥시멈 프리픽스 렝스 매치(Maxinum Prefix Length Match)라고도 한다.
해당 작업은 부정확한 정보 중 가장 비슷한 경로를 찾기 때문에 라우터에서 많은 부하가 걸린다.
이를 줄이기 위해 한 번 스위칭 작업을 수행한 정보는 캐시에 저장되고 뒤에 들어오는 패킷은 라우팅 테이블을 확인하기 전에 캐시를 먼저 확인한다. 이런 캐시 정보에는 출발지 IP, 목적지 IP, 포트 번호, 넥스트 홉 정보를 가질 수 있다.
라우팅, 스위칭 우선순위
라우팅 테이블은 가장 좋은 경로 정보만 모아놓은 핵심정보이다. 일반적인 경로 정보를 모아놓은 토폴로지 테이블에서 좋은 경로 정보의 우선 순의는 경로 정보를 받은 방법과 거리를 기준으로 한다.
목적지 네트워크 정보가 동일한 서브넷을 사용하는 경우, 정보를 얻은 소스에 따라 가중치를 정하게 된다.
이 가중치 값은 라우팅 정보의 분류와 마찬가지로 크게 3 가지로 나눌 수 있다.
- 내가 갖고 있고 있는 네트워크(다이렉트 커넥티드)
- 내가 경로를 직접 지정한 네트워크(스태틱 라우팅)
- 경로를 전달받은 네트워크(다이나믹 라우팅)
이 중에 가장 우선순위가 가장 높은 것은 라우터에 바로 연결된 네트워크, 다이렉트 커넥티드이다. 이는 라우터에 바로 붙은 대역이므로 경로 선정 시 우선순위가 가장 높다.
다음은 스태틱 라우팅이다. 목적지 네트워크에 대한 경로 정보를 관리자가 직접 입력하기 때문에 신뢰도가 높아 로컬 네트워크 다음으로 우선순위가 높다
마지막으로 다이나믹 라우팅이다. 이 경우는 다른 라우터를 통해 경로를 전달받기 때문에 우선순위가 낮다.
이런 기본적인 우선순위가 정해져 있지만 관리자가 우선순위를 조정할 수 있다. 이런 우선순위를 AD(Administrative Distance)라고 부르며 라우터 생산업체마다 AD 값이 조금씩 다르다.
| 우선순위 | 기본 디스턴스 |
| 0 | Connected Interface(다이렉트 커넥티드) |
| 1 | Static Route(스태틱 라우팅) |
| 20 | External BGP |
| 110 | OSPF |
| 115 | IS-IS |
| 120 | RIP |
| 200 | Internal BGP |
| 256 | Unknown |
가중치 값이 동일한 경우에는 코스트(Cost) 값으로 우선순위를 정한다. 코스트 값까지 똑같다면 ECMP(Equal-Cost Multi-Path) 기능으로 동일한 코스트 값을 가진 경로 값 정보를 모두 활용해 트래픽을 분산한다.
패킷을 스위칭할 때는 롱기스트 프리픽스 매치 기법으로 우선순위를 정한다.
라우터의 라우팅, 스위칭 역할을 하나로 묶어 다시 설명하면 전체적인 우선순위는 아래와 같다.
| 우선순위 | 구분 | 적용 방법 |
| 1 | 롱기스트 매치 | 스위칭 |
| 2 | AD(관리 거리) | 라우팅 |
| 3 | 코스트 | 라우팅 |
| 4 | 부하 분산(ECMP) | 라우팅 |
라우터와 관련 정보는 이와 같으며 라우팅 우선순위와 각 라우팅 설정방법에 대해서는 다음 게시물에서 알아보겠다.
'CS > 네트워크' 카테고리의 다른 글
| NAT/PAT 란? (0) | 2022.07.06 |
|---|---|
| 라우팅 설정 방법 (0) | 2022.06.30 |
| STP(Spanning Tree Protocol) (0) | 2022.06.22 |
| VLAN(Virtual Local Area Network) (0) | 2022.06.21 |
| 스위치(switch)란? (0) | 2022.06.21 |
라우터는 3 계층에서 동작하고 이름처럼 경로를 지정해주는 장비이다.
라우터에 들어오는 패킷의 목적지 IP 주소를 확인하고 자신이 가진 경로 정보를 이용해 패킷의 최적의 경로로 포워딩한다.
또한 원격지 네트워크와 연결할 때 필수 네트워크 장비이며 네트워크를 구성하는 핵심 장비이다.
라우터의 동작 방식과 역할
라우터는 다양한 경로 정보를 수집해 최적의 경로를 라우팅 테이블에 저장한 후 패킷이 라우터로 들어오면 도착지 IP 주소와 라우팅 테이블을 비교해 최선의 경로로 패킷을 내보낸다. 이 말은 패킷의 목적지 주소가 라우팅 테이블에 없다면 패킷을 버린다는 것이다.
패킷 포워딩 과정에서 기존 2 계층 헤더 정보를 제거한 후 새로운 2 계층 헤더를 만든다.
이제부터 라우터의 동작방식인 경로 지정, 브로드캐스트 컨트롤, 프로토콜 변환 알아보자.
경로 지정
라우터는 도착지의 IP 주소를 확인하는데 IP주소는 네트워크 주소와 호스트 주소로 나뉜 계층 구조를 기반으로 설계되어 로컬 네트워크와 원격지 네트워크를 구분할 수 있고 네트워크 주소를 기반으로 경로를 찾을 수 있기 때문에 IP주소를 확인한다.
IP 주소란
IP 주소 2 계층의 물리 주소인 MAC 주소와 달리 IP 주소는 3 계층의 논리 주소를 사용한다. 대부분의 네트워크가 TCP/IP로 동작하므로 IP 주소체계를 이해하는 것이 네트워크 이해에 매주 중요하다. IP
rooftoproom-whale.tistory.com
그래서 라우터는 원격지에 있는 적절한 경로로 패킷을 포워딩할 수 있으며 이러한 역할을 2 가지로 구분해 수행한다.
경로 정보를 얻는 역할과 얻은 경로 정보를 확인하고 패킷을 포워딩하는 역할이다.
다양한 방법으로 경로 정보를 얻을 수 있는데 총 3 가지의 방법이 있다.
- IP 주소를 입력하면 자연스럽게 인접 네트워크 정보를 얻는 방법
- 관리자가 직접 경로 정보를 입력하는 방법
- 라우터끼리 서로 경로 정보를 자동으로 교환하는 방법
브로드캐스트 컨트롤(Broadcast Control)
스위치는 패킷의 도착지 주소를 모르면 어딘가에 존재할지 모를 장비와의 통신을 위해 플러딩해 패킷을 모든 포트로 전송한다. LAN 어딘가에 도착지가 있다고 가정하고 보내기 때문에 쓸모없는 패킷이 전송되어 전체 네트워크에 무리가 갈 수 있다고 생각할 수 있지만 LAN은 크기가 작고 도착지 NIC에서 자신의 주소와 패킷의 주소가 다르면 패킷을 버리기 때문에 플러딩이 네트워크에 큰 무리는 주지 않는다.
반면 라우터는 패킷을 원격지로 보내는 것이 목표이기때문에 3 계층에서 동작하고 도착지가 명확할 때만 통신을 허락한다.
만약 스위치처럼 동작한다면 목적지가 다르거나 명확하지 않은 패킷이 플러딩되어 인터넷에 이러한 패킷이 가득 차 통신 불능 상태가 될 수 있다.
라우터는 바로 연결되어 있는 네트워크 정보를 제외하고 경로 습득 설정을 하지 않으면 패킷을 포워딩할 수 없다.
라우터의 기본 동작은 멀티캐스트 정보를 습득하지 않고 브로드캐스트 패킷을 전달하지 않는다. 이 기능을 이용해 브로드캐스트가 다른 네트워크로 전파하는 것을 막을 수 있는데 이 기능을 브로드캐스트 컨트롤/멀티캐스트 컨트롤 이라고 한다.
그래서 브로드캐스트가 많이 발생한다면 라우터로 네트워크를 분리해 성능을 높일 수 있다.
프로토콜 변환
라우터의 또 다른 역할은 서로 다른 프로토콜로 구성된 네트워크를 연결하는 것이다.
현대에는 이더넷으로 수렴되므로 이 역할이 줄어들었지만 과거에는 LAN 프로토콜과 WAN 프로토콜이 전혀 달라 원격지 네트워크와 통신하려면 LAN 기술이 WAN 기술로 변환되어야만 가능했는데 이 역할을 라우터가 담당했다.
라우터에 패킷이 들어오면 2계층까지의 헤더 정보를 벗겨내고 3 계층 주소를 확인한 후 2 계층 헤더 정보를 새로 만들어 외부로 내보낸다. 그래서 라우터에 들어올 때와 나갈 때 헤더 정보가 다른 것이다.
이 기능을 이용하면 전혀 다른 기술 간 변환이 가능하다. 저속 전용회선에서 WAN 구간은 PPP와 같은 WAN 프로토콜이 사용되고 LAN 구간은 이더넷 프로토콜이 사용된다. LAN 구간에서 패킷이 라우터를 지나면서 2 계층까지의 헤더가 벗겨지고 WAN 구간으로 패킷이 나올 때 PPP 헤더로 변경되어 프로토콜이 변환된다.
경로 지정 - 라우팅/스위칭
라우터가 패킷을 처리할 때는 크게 두 가지 작업을 수행한다.
- 경로 정보를 얻어 경로 정보를 정리하는 역할
- 정리된 경로 정보를 기반으로 패킷을 포워딩하는 역할
라우터는 본인이 모르는 목적지를 가진 패킷을 버리기때문에 패킷이 들어오기 전 경로 정보를 충분히 수집하고 있어야한다.
클래스리스 네트워크로 전환된 후에는 같은 클래스에 있는 주소조차 서브네팅된 상태로 분산되어 존재하므로 경로 정보가 기존보다 훨씬 많아졌다. 그렇기 때문에 라우터는 많은 경로 정보를 얻어 최적의 경로 정보인 라우팅 테이블을 적절히 유지해야 한다.
라우터는 서브넷 단위로 라우팅 정보를 습득하고 라우팅 정보를 최적화하기 위해 서머리(Summary) 작업을 통해 여러 개의 서브넷 정보를 뭉쳐 전달한다. 그래서 패킷 목적지 주소와 라우팅 테이블 정보가 정확히 일치하지 않더라도 수많은 정보 중 목적지에 가장 근접한 정보를 찾아 패킷을 포워딩해야 한다.
라우팅 동작과 라우팅 테이블
현대 인터넷에서는 인접한 라우터까지만 경로를 지정하면 인접 라우터에서 최적의 경로를 다시 파악한 후 라우터로 패킷을 포워딩한다. 네트워크 한 단계씩 뛰어넘는다는 의미로 홉-바이-홉(Hop-by-Hop) 라우팅이라 부르고 인접한 라우터를 넥스트 홉(Next Hop)이라 부른다.
라우터는 패킷이 목적지로 가는 전체 경로를 파악하지 않고 최적의 넥스트 홉을 선택해 보내준다.
넥스트 홉을 지정할 때는 3 가지 방법을 사용할 수 있다.
- 다음 라우터의 IP를 지정하는 방법(넥스트 홉 IP 주소)
- 라우터의 나가는 인터페이스를 지정하는 방법
- 라우터의 나가는 인터페이스와 다음 라우터의 IP를 동시에 지정하는 방법
라우터에서 넥스트 홉을 지정할 때는 상대방 라우터의 인터페이스 IP 주소를 지정하는 방법을 사용한다.
상대방 넥스트 홉 라우터의 IP를 모르더라도 MAC 주소 정보를 알아낼 수 있을 때만 라우터의 나가는 인터페이스를 지정하는 방법을 쓸 수 있다. WAN 구간 전용선에서 PPP(Point-to-Point)나 HLDC(High Level Datalink Control)와 같은 프로토콜을 사용해 상대방의 MAC 주소를 알 필요가 없거나 상대방 라우터에서 프록시 ARP가 동작해 IP 주소를 모르더라도 상대방의 MAC 주소를 알 수 있을때와 같은 한정된 조건에서만 사용할 수 있다.
이런 경우는 특수한 경우이므로 상대방 IP 주소를 넥스트 홉으로 지정해야 한다.
인터페이스를 설정할 때 라우터의 나가는 물리 인터페이스를 지정하는 것이 일반적이지만 IP주소와 인터페이스를 동시에 사용할 때는 VLAN 인터페이스와 같은 논리적인 인터페이스를 사용할 수 있다.
PPP(Point-to-Point) : 두 통신 노드 간의 직접적인 연결을 위해 일반적으로 사용되는 데이터 링크 프로토콜
HLDC(High Level Datalink Control) : 컴퓨터가 일대일 혹은 일대다로 연결된 환경에 데이터의 송수신 기능을 제공
프록시 ARP : 한 호스트(일반적으로 라우터)가 다른 시스템에 대해 의도된 ARP 요청에 응답하는 기술
라우터 인터페이스 : 라우터의 접속 가능한 포트
라우터는 출발지와 상관없이 목적지 주소와 라우팅 테이블을 비교해 어느 경로로 포워딩할지 결정한다.
그래서 라우팅 테이블을 만들 때는 목적지 정보만 수집하고 패킷이 들어오면 목적지 주소를 확인해 패킷을 넥스트 홉으로 포워딩한다.
라우팅 테이블에 저장하는 데이터는 1. 목적지 주소, 2. 넥스트 홉 IP 주소, 나가는 로컬 인터페이스(선택 가능)이다.
라우터에는 패킷의 출발지 주소를 이용하는 PBR(Policy-Based Routing) 기능이 있지만 라우팅 테이블은 출발지 주소를 이용하지 않기 때문에 이 기능을 사용할 수 없다.
<참고> 루프가 없는(Loop Free) 3 계층 : TTL(Time To Live)
3 계층의 IP 헤더에는 패킷이 네트워크에 살아 있을 수 있는 시간을 제한하는 TTL이라는 필드가 있다.
인터넷 구간에 쓸모없는 패킷이 돌아다녀 대역폭을 낭비하는 것을 막기 위해 주소가 불분명한 것은 라우터가 버린다.
허나 이는 정상적으로 운영되던 사이트가 갑자기 없어질 수 있고 대안 경로를 찾다가 두 대의 라우터가 서로 마주 봐 루프가 생길 수 있다.
그래서 모든 패킷은 TTL이라는 수명 값을 가지고 있고 이 값이 0이 되면 네트워크 장비에서 버려진다.
이때 TTL의 Time은 실제 초와 같은 시간이 아니라 홉을 지칭하며 하나의 홉을 지날 시 1씩 줄어든다.
라우팅(라우터가 경로 정보를 얻는 방법)
경로 정보를 얻는 방법은 아래와 같이 총 3 가지가 있다.
- 다이렉트 커넥티드
- 스태틱 라우팅
- 다이나믹 라우팅
이 방법들을 통해 경로를 수집하고 목적지에 대한 최적의 경로를 선정해 라우팅 테이블을 만든다.
먼저 다이렉트 커넥티드에 대해 알아보자
다이렉트 커넥티드
IP주소를 입력할 때 사용된 IP 주소와 서브넷 마스크로 해당 IP 주소가 속한 네트워크 주소 정보를 알 수 있다.
라우터나 PC는 이 정보로 해당 네트워크에 대한 라우팅 테이블을 자동으로 만든다. 이 경로 정보를 다이렉트 커넥티드 라고 한다.
이 정보는 인터페이스에 IP를 설정하면 자동 생성되는 정보이므로 정보를 강제로 지울 수 없고 해당 네트워크 설정을 삭제하거나 해당 네트워크 인터페이스가 비활성화되어야만 자동으로 사라진다.
스태틱 라우팅
스태틱 라우팅은 정적, 말 그대로 관리자가 목적지 네트워크와 넥스트 홉을 직접 지정해 경로 정보를 입력하는 것이다.
다이렉트 커넥티드처럼 연결된 인터페이스 정보가 삭제, 비활성화되면 라우팅 정보가 자동 삭제된다.
허나 물리 인터페이스가 아닌 논리 인터페이스는 물리 인터페이스가 비활성화되더라도 라우팅 테이블에서 사라지지 않을 수 있다.
R1은 다이렉트 커넥티드 학습된 상태에서 20.20.20.20/24에 대한 네트워크 정보가 없다. R1의 10.10.10.0/24 네트워크가 R2의 20.20.20.20과 통신하려면 넥스트 홉을 1.1.1.2로 스태틱 라우팅을 설정해야 한다.
네트워크 통신은 양뱡향이기 때문에 이때 되돌아오는 패킷을 고려해야 한다. R2 또한 10.10.10.0/24 네트워크에 대한 정보가 없기 때문에 스태틱 라우팅을 통해 10.10.10.0/24 네트워크와 넥스트 홉 1.1.1.1을 추가한다.
다이나믹 라우팅
스태틱 라우팅은 변화가 적은 네트워크에서 손쉽게 관리할 수 있는 방법이지만 큰 네트워크에서는 관리에 무리가 있다.
이는 라우터 너머의 다른 라우터의 상태 정보를 파악할 수 없어 라우터 사이의 회선이나 라우터에 장애가 발생하면 장애 상황을 파악하고 대체 경로로 패킷을 보낼 수 없기 때문이다.
다이나믹 라우팅은 이런 스태틱 라우팅의 단점을 보완해준다. 라우터끼리 자신이 알고 있는 경로 정보나 링크 상태 정보를 교환해 전체 네트워크 정보를 학습한다. 주기적으로 또는 상태 정보가 변경될 때마다 정보 교환을 하기 때문에 장애가 발생한다면 대체 경로로 패킷을 포워딩할 수 있다.
이러한 점 덕분에 현재 대부분의 네트워크는 다이나믹 라우팅을 사용한다.
스위칭(라우터가 경로를 지정하는 방법)
스위칭이란 패킷이 들어와 라우팅 테이블을 참조하고 최적의 경로를 찾아 라우터 외부로 포워딩하는 작업을 말한다.
2계층의 스위치와 이름이 비슷하지만 라우터가 패킷 경로를 지정해 보내는 작업을 말한다.
패킷을 최선의 경로로 내보낼 때도 여러 가지를 고려해야 한다. 들어온 패킷의 목적지가 라우팅 테이블에 있는 정보와 완벽히 일치할 때도 있지만 비슷하게 일치하거나 일치하지 않는 경우도 생길 수 있기 때문이다.
라우팅 테이블에 일치하는 경로 정보가 없지만 가장 가까운 경로 정보를 매칭해주는데 이를 롱기스트 프리픽스 매치(Longest Prefix Match)라고 한다.
<참고>롱기스트 프리픽스 매치(Longest Prefix Match)
라우터가 패킷을 포워딩할 때 자신이 갖고 있는 라우팅 테이블에서 가장 좋은 항목을 찾는 알고리즘.
맥시멈 프리픽스 렝스 매치(Maxinum Prefix Length Match)라고도 한다.
해당 작업은 부정확한 정보 중 가장 비슷한 경로를 찾기 때문에 라우터에서 많은 부하가 걸린다.
이를 줄이기 위해 한 번 스위칭 작업을 수행한 정보는 캐시에 저장되고 뒤에 들어오는 패킷은 라우팅 테이블을 확인하기 전에 캐시를 먼저 확인한다. 이런 캐시 정보에는 출발지 IP, 목적지 IP, 포트 번호, 넥스트 홉 정보를 가질 수 있다.
라우팅, 스위칭 우선순위
라우팅 테이블은 가장 좋은 경로 정보만 모아놓은 핵심정보이다. 일반적인 경로 정보를 모아놓은 토폴로지 테이블에서 좋은 경로 정보의 우선 순의는 경로 정보를 받은 방법과 거리를 기준으로 한다.
목적지 네트워크 정보가 동일한 서브넷을 사용하는 경우, 정보를 얻은 소스에 따라 가중치를 정하게 된다.
이 가중치 값은 라우팅 정보의 분류와 마찬가지로 크게 3 가지로 나눌 수 있다.
- 내가 갖고 있고 있는 네트워크(다이렉트 커넥티드)
- 내가 경로를 직접 지정한 네트워크(스태틱 라우팅)
- 경로를 전달받은 네트워크(다이나믹 라우팅)
이 중에 가장 우선순위가 가장 높은 것은 라우터에 바로 연결된 네트워크, 다이렉트 커넥티드이다. 이는 라우터에 바로 붙은 대역이므로 경로 선정 시 우선순위가 가장 높다.
다음은 스태틱 라우팅이다. 목적지 네트워크에 대한 경로 정보를 관리자가 직접 입력하기 때문에 신뢰도가 높아 로컬 네트워크 다음으로 우선순위가 높다
마지막으로 다이나믹 라우팅이다. 이 경우는 다른 라우터를 통해 경로를 전달받기 때문에 우선순위가 낮다.
이런 기본적인 우선순위가 정해져 있지만 관리자가 우선순위를 조정할 수 있다. 이런 우선순위를 AD(Administrative Distance)라고 부르며 라우터 생산업체마다 AD 값이 조금씩 다르다.
| 우선순위 | 기본 디스턴스 |
| 0 | Connected Interface(다이렉트 커넥티드) |
| 1 | Static Route(스태틱 라우팅) |
| 20 | External BGP |
| 110 | OSPF |
| 115 | IS-IS |
| 120 | RIP |
| 200 | Internal BGP |
| 256 | Unknown |
가중치 값이 동일한 경우에는 코스트(Cost) 값으로 우선순위를 정한다. 코스트 값까지 똑같다면 ECMP(Equal-Cost Multi-Path) 기능으로 동일한 코스트 값을 가진 경로 값 정보를 모두 활용해 트래픽을 분산한다.
패킷을 스위칭할 때는 롱기스트 프리픽스 매치 기법으로 우선순위를 정한다.
라우터의 라우팅, 스위칭 역할을 하나로 묶어 다시 설명하면 전체적인 우선순위는 아래와 같다.
| 우선순위 | 구분 | 적용 방법 |
| 1 | 롱기스트 매치 | 스위칭 |
| 2 | AD(관리 거리) | 라우팅 |
| 3 | 코스트 | 라우팅 |
| 4 | 부하 분산(ECMP) | 라우팅 |
라우터와 관련 정보는 이와 같으며 라우팅 우선순위와 각 라우팅 설정방법에 대해서는 다음 게시물에서 알아보겠다.
'CS > 네트워크' 카테고리의 다른 글
| NAT/PAT 란? (0) | 2022.07.06 |
|---|---|
| 라우팅 설정 방법 (0) | 2022.06.30 |
| STP(Spanning Tree Protocol) (0) | 2022.06.22 |
| VLAN(Virtual Local Area Network) (0) | 2022.06.21 |
| 스위치(switch)란? (0) | 2022.06.21 |