
스택은 데이터의 입력과 출력이 이루어지는 공간이 top 하나뿐이고 FILO or LIFO 인 자료구조이다.
큐는 이와 반대로 입력과 출력 공간이 따로 존재하고 제일 먼저 들어간 데이터가 제일 먼저 나오는(FIFO) 자료구조이다.
그렇다면 큐를 왜 사용하는 것일까? 데이터 입력이 폭주하는 경우를 생각해보자.
먼저 입력받은 데이터의 처리가 안 끝났는데 그 뒤에 새로운 데이터가 계속 입력되면 그 데이터는 보관할 곳이 없기때문에 모두 버리게 된다. 이때 밀려드는 데이터를 저장하기위해 큐를 쓴다.
우리는 이런 구조를 자바에서 쉽게 찾아볼 수 있다. 바로 버퍼(Buffer)가 큐를 사용한다.
큐의 주요 기능 : 삽입과 제거
큐의 기본적인 구조는 아래와 같다.
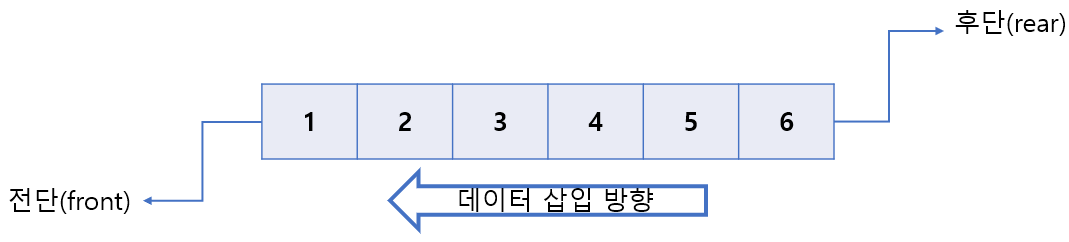
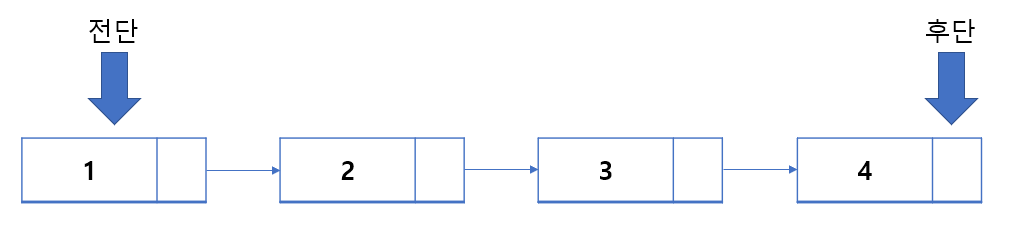
큐는 삽입은 후단(rear), 제거는 전단(front) 에서 일어난다.
- 삽입 : 후단에 데이터가 삽입되고 데이터는 새로운 후단이 된다.
- 제거 : 전단에서 데이터가 제거되고 제거된 데이터 다음 노드가 새로운 전단이 된다.
큐를 구현하는 방식
큐를 구현방식에는 순환방식과 링크드방식이 있다. 우선 순환 큐를 먼저 알아보자.
순환 큐
순환 큐는 고정된 크기의 배열로 구현한다. 그러면 스택처럼 순환하지 않는 상태로 구현하면 되지 않을까라는 의문이 든다.
허나 큐는 스택과 달리 데이터 삽입/삭제가 시작과 끝 2군데에서 이루어지기때문에 일반적인 배열로 구현할 경우 비용 문제가 나타나게 된다.
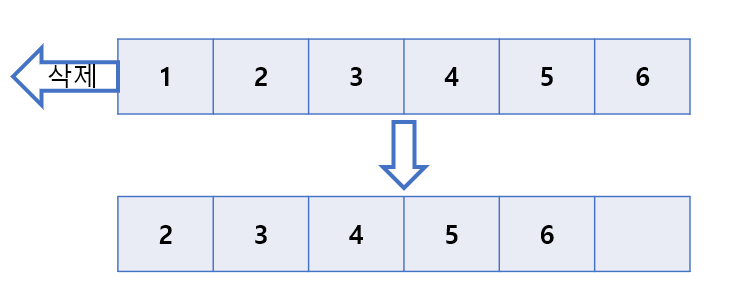
삭제를 하면 전단의 데이터가 사라지고 나머지 요소들을 한 칸씩 앞으로 옮겨야하는 비용이 발생한다. 큐의 크기가 n이라면 n-1번의 이동이 필요하게 된다. 이를 해결하기 위해 전단이라는 변수를 도입해 요소를 옮기지말고 변경된 전단의 위치만 관리하고 후단도 도입해 삽입이 일어날 때마다 변경되는 후단의 위치를 관리한다.
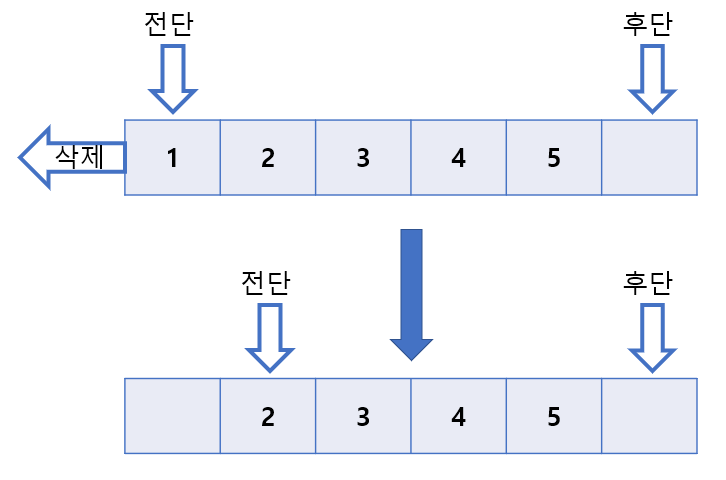
이렇게하면 비용문제를 해결할 수 있지만 계속 삭제가 일어난다면 가용 용량이 줄어들게 된다. 그래서 순환 방식을 이용한다.
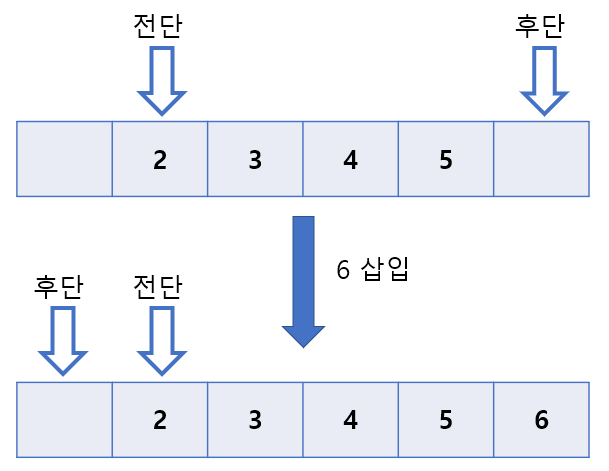
배열의 끝에서 데이터가 추가되면 후단은 배열의 첫번째로 이동하는 순환방식을 사용한다. 후단과 전단이 만난다면 데이터가 가득 찬 상태가 되는것이다.
그럼 비어있거나 가득찬 상태는 전단, 후단이 같으니 어떻게 구별할까 라는 의문이 든다.
이를 해결하는 방법은 큐 배열을 생성할 때 실제 용량보다 1만큼 더 크게 만들어 전단과 후단사이를 비우는 것이다. 그럼 비어있을땐 전단과 후단이 같고 가득 찬 상태일때는 후단이 전단보다 1 작은 값을 갖게된다.
순환 큐 구현하기
순환 큐의 주요연산은 아래와 같다.
- 선언
- 생성
- 삽입
- 제거
- 공백, 포화상태
순환 큐 선언과 생성
순환 큐 클래스는 용량(Capacity), 전단의 위치(Front), 후단의 위치(Rear), 배열을 갖고 있다
class CircularQueue<T>
{
private final int Capacity;
private int front;
private int rear;
private final Object[] data;
public CircularQueue(int capacity) {
this.Capacity = capacity;
this.data = new Object[this.Capacity + 1];
}
public int getCapacity() {
return Capacity;
}
public int getFront() {
return front;
}
public int getRear() {
return rear;
}
}Capacity에는 배열의 크기가 저장되는데 이 값은 실제 용량보다 하나 작다. 이는 공백/포화 상태를 구분할 데이터를 하나 더 갖고 있어야하기 때문이다.
Front, Rear는 배열내의 인덱스를 갖는다. 이때 Rear는 실제의 후단보다 1 더 큰 값을 갖는다.
순환 큐 삽입
삽입 연산은 후단의 위치를 가리키는 Rear가 핵심이다.
public void enqueue(T newData)
{
int position = 0;
if(rear == Capacity)
{
position = rear;
rear = 0;
}
else position = rear++;
data[position] = newData;
}데이터를 삽입할 때는 rear 인덱스에 값을 넣으며 rear를 증가시킨다. 이때 고려해야할 사항은 rear가 배열의 끝에 있는 경우다.
이때에는 해당 위치에 데이터를 넣고 큐가 순환할 수 있게 rear를 인덱스 0으로 위치시킨다.
순환 큐 제거
public Object dequeue()
{
int position = front;
if(front == Capacity) front = 0;
else front++;
Object returnValue = data[position];
data[position] = null;
return returnValue;
}삽입과 반대로 제거에서는 front가 핵심이다. position에 현재 front를 저장 후 front를 증가시킨다.
이때에도 순환할때를 고려해 front가 배열 끝일 경우 처음으로 초기화한다.
공백, 포화상태 확인
public boolean isEmpty()
{
return front == rear;
}
public boolean isFull()
{
return (front < rear) ? (rear - front) == Capacity : (rear + 1) == front;
}공백이란 것은 전단, 후단 인덱스가 같다는 얘기이므로 같을시 true를 반환한다.
포화상태를 확인할때는 2가지 경우가 있는데 먼저 전단이 후단 앞에 위치하는 경우에는 전단, 후단과의 차가 큐의 용량이랑 같은지 확인하고 전단이 후단 뒤에 위치하는 경우는 순환하고있는 상태이기때문에 rear에 1를 더한 값이 front랑 같은지 확인해야한다.
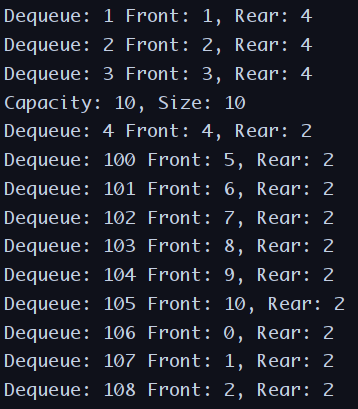
예제소스
public class CircularQueueTest
{
public static void main(String[] args)
{
CircularQueue<Integer> queue = new CircularQueue<>(10);
queue.enqueue(1);
queue.enqueue(2);
queue.enqueue(3);
queue.enqueue(4);
for (int i = 0; i < 3; i++)
{
System.out.print("Dequeue: " + queue.dequeue());
System.out.println(" Front: " + queue.getFront() + ", Rear: " + queue.getRear());
}
int data = 100;
while (!queue.isFull())
{
queue.enqueue(data++);
}
System.out.println("Capacity: " + queue.getCapacity() + ", Size: " + queue.getSize());
while (!queue.isEmpty())
{
System.out.print("Dequeue: " + queue.dequeue());
System.out.println(" Front: " + queue.getFront() + ", Rear: " + queue.getRear());
}
}
}
링크드 큐
링크드 큐는 데이터, 다음 노드를 가리키는 포인터 로 구성된 노드를 통해 큐를 구현하는 것이다. 링크드리스트의 구현 방식과 유사하다. 포인터가 추가되었기 때문에 추가 연산을 하므로 순환 큐보다는 성능이 떨어지지만 가득찬다는 개념이 없이 계속 추가 가능하다는 장점이 있다.
링크드 큐 구현하기
링크드 큐의 주요 연산은 아래와 같다.
- 선언
- 생성
- 삽입
- 제거
- 공백상태
순환 큐와 달리 포화상태 확인이 없는데 이는 링크드 큐가 데이터를 계속 추가 가능하기때문에 포화 상태인지 확인할 수 없다.
링크드 큐 선언과 생성
class Node
{
private T data;
private Node nextNode;
public Node(T data) {
this.data = data;
}
public T getData() {
return data;
}
}먼저 노드 생성이다. 다음 노드의 참조가 추가되고 노드 생성시 데이터를 입력받고 nextNode는 null 상태로 시작한다.
public class LinkedQueue<T>
{
private Node front;
private Node rear;
private int count;
}순환 큐와 같이 전단(front), 후단(rear) 가 존재하고 데이터의 갯수를 표시할 count 변수도 존재한다.
링크드 큐 삽입
삽입할 때 후단에 새로운 노드를 붙이면 끝이다.
public void enqueue(T newData)
{
Node newNode = new Node(newData);
if(front == null)
{
front = newNode;
rear = newNode;
}
else
{
rear.nextNode = newNode;
rear = rear.nextNode;
}
count++;
}이때 두가지 경우를 생각해야한다.
큐가 완전히 빈값을 경우 front가 null이기 때문에 이때 추가되는 노드는 front, rear를 둘 다 갖고 있다.
이외의 경우는 후단의 nextNode를 추가되는 노드(newNode)로, 후단(Rear)을 후단의 nextNode로 설정한다.
추가된 후에는 count를 통해 갯수를 증가한다.
링크드 큐 제거
노드를 제거할 때 전단의 다음 노드를 새로운 전단으로 만들고 전단이었던 노드를 반환한다.
public Node dequeue()
{
Node frontNode = front;
if(front.nextNode == null)
{
front = null;
rear = null;
}
else
{
front = front.nextNode;
}
count--;
return frontNode;
}삽입할 때와 마찬가지로 두가지 경우가 존재하며 제거 완료시 다른 노드가 존재하지않는다면 전단, 후단 null 처리
이외는 전단을 옮겨주기만 하면 된다. 제거 후에는 count를 감소시킨다.
공백상태 확인
public boolean isEmpty()
{
return front == null;
}전단이 null란 얘기는 큐가 비어있다는 말이므로 true를 반환한다.
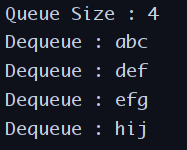
예제소스
public class LinkedQueueTest {
public static void main(String[] args) {
LinkedQueue<String> queue = new LinkedQueue<>();
queue.enqueue("abc");
queue.enqueue("def");
queue.enqueue("efg");
queue.enqueue("hij");
System.out.println("Queue Size : " + queue.getSize());
while(!queue.isEmpty())
{
LinkedQueue<String>.Node popped = queue.dequeue();
System.out.println("Dequeue : " + popped.getData());
}
}
}
요약
이렇게 구현해봄으로써 알 수 있는 장단점으로는
장점
- 데이터가 입력된 순서대로 처리해야 할 상황에 좋다.
단점
- 스택과 마찬가지로 중간 위치에 데이터 접근하려면 모든 데이터를 꺼내면서 찾아야한다.
'CS > 자료구조' 카테고리의 다른 글
| 이진 트리(Binary Tree) 개념 및 구현 (0) | 2022.06.17 |
|---|---|
| 트리(Tree) 개념 및 구현 (0) | 2022.06.16 |
| 스택(Stack) 개념 및 구현 (0) | 2022.05.25 |
| 더블 링크드리스트(Doubly Linked List) 개념과 구현 (0) | 2022.05.20 |
| 링크드리스트(LinkedList) 개념 및 구현 (0) | 2022.05.20 |
스택은 데이터의 입력과 출력이 이루어지는 공간이 top 하나뿐이고 FILO or LIFO 인 자료구조이다.
큐는 이와 반대로 입력과 출력 공간이 따로 존재하고 제일 먼저 들어간 데이터가 제일 먼저 나오는(FIFO) 자료구조이다.
그렇다면 큐를 왜 사용하는 것일까? 데이터 입력이 폭주하는 경우를 생각해보자.
먼저 입력받은 데이터의 처리가 안 끝났는데 그 뒤에 새로운 데이터가 계속 입력되면 그 데이터는 보관할 곳이 없기때문에 모두 버리게 된다. 이때 밀려드는 데이터를 저장하기위해 큐를 쓴다.
우리는 이런 구조를 자바에서 쉽게 찾아볼 수 있다. 바로 버퍼(Buffer)가 큐를 사용한다.
큐의 주요 기능 : 삽입과 제거
큐의 기본적인 구조는 아래와 같다.
큐는 삽입은 후단(rear), 제거는 전단(front) 에서 일어난다.
- 삽입 : 후단에 데이터가 삽입되고 데이터는 새로운 후단이 된다.
- 제거 : 전단에서 데이터가 제거되고 제거된 데이터 다음 노드가 새로운 전단이 된다.
큐를 구현하는 방식
큐를 구현방식에는 순환방식과 링크드방식이 있다. 우선 순환 큐를 먼저 알아보자.
순환 큐
순환 큐는 고정된 크기의 배열로 구현한다. 그러면 스택처럼 순환하지 않는 상태로 구현하면 되지 않을까라는 의문이 든다.
허나 큐는 스택과 달리 데이터 삽입/삭제가 시작과 끝 2군데에서 이루어지기때문에 일반적인 배열로 구현할 경우 비용 문제가 나타나게 된다.
삭제를 하면 전단의 데이터가 사라지고 나머지 요소들을 한 칸씩 앞으로 옮겨야하는 비용이 발생한다. 큐의 크기가 n이라면 n-1번의 이동이 필요하게 된다. 이를 해결하기 위해 전단이라는 변수를 도입해 요소를 옮기지말고 변경된 전단의 위치만 관리하고 후단도 도입해 삽입이 일어날 때마다 변경되는 후단의 위치를 관리한다.
이렇게하면 비용문제를 해결할 수 있지만 계속 삭제가 일어난다면 가용 용량이 줄어들게 된다. 그래서 순환 방식을 이용한다.
배열의 끝에서 데이터가 추가되면 후단은 배열의 첫번째로 이동하는 순환방식을 사용한다. 후단과 전단이 만난다면 데이터가 가득 찬 상태가 되는것이다.
그럼 비어있거나 가득찬 상태는 전단, 후단이 같으니 어떻게 구별할까 라는 의문이 든다.
이를 해결하는 방법은 큐 배열을 생성할 때 실제 용량보다 1만큼 더 크게 만들어 전단과 후단사이를 비우는 것이다. 그럼 비어있을땐 전단과 후단이 같고 가득 찬 상태일때는 후단이 전단보다 1 작은 값을 갖게된다.
순환 큐 구현하기
순환 큐의 주요연산은 아래와 같다.
- 선언
- 생성
- 삽입
- 제거
- 공백, 포화상태
순환 큐 선언과 생성
순환 큐 클래스는 용량(Capacity), 전단의 위치(Front), 후단의 위치(Rear), 배열을 갖고 있다
class CircularQueue<T>
{
private final int Capacity;
private int front;
private int rear;
private final Object[] data;
public CircularQueue(int capacity) {
this.Capacity = capacity;
this.data = new Object[this.Capacity + 1];
}
public int getCapacity() {
return Capacity;
}
public int getFront() {
return front;
}
public int getRear() {
return rear;
}
}Capacity에는 배열의 크기가 저장되는데 이 값은 실제 용량보다 하나 작다. 이는 공백/포화 상태를 구분할 데이터를 하나 더 갖고 있어야하기 때문이다.
Front, Rear는 배열내의 인덱스를 갖는다. 이때 Rear는 실제의 후단보다 1 더 큰 값을 갖는다.
순환 큐 삽입
삽입 연산은 후단의 위치를 가리키는 Rear가 핵심이다.
public void enqueue(T newData)
{
int position = 0;
if(rear == Capacity)
{
position = rear;
rear = 0;
}
else position = rear++;
data[position] = newData;
}데이터를 삽입할 때는 rear 인덱스에 값을 넣으며 rear를 증가시킨다. 이때 고려해야할 사항은 rear가 배열의 끝에 있는 경우다.
이때에는 해당 위치에 데이터를 넣고 큐가 순환할 수 있게 rear를 인덱스 0으로 위치시킨다.
순환 큐 제거
public Object dequeue()
{
int position = front;
if(front == Capacity) front = 0;
else front++;
Object returnValue = data[position];
data[position] = null;
return returnValue;
}삽입과 반대로 제거에서는 front가 핵심이다. position에 현재 front를 저장 후 front를 증가시킨다.
이때에도 순환할때를 고려해 front가 배열 끝일 경우 처음으로 초기화한다.
공백, 포화상태 확인
public boolean isEmpty()
{
return front == rear;
}
public boolean isFull()
{
return (front < rear) ? (rear - front) == Capacity : (rear + 1) == front;
}공백이란 것은 전단, 후단 인덱스가 같다는 얘기이므로 같을시 true를 반환한다.
포화상태를 확인할때는 2가지 경우가 있는데 먼저 전단이 후단 앞에 위치하는 경우에는 전단, 후단과의 차가 큐의 용량이랑 같은지 확인하고 전단이 후단 뒤에 위치하는 경우는 순환하고있는 상태이기때문에 rear에 1를 더한 값이 front랑 같은지 확인해야한다.
예제소스
public class CircularQueueTest
{
public static void main(String[] args)
{
CircularQueue<Integer> queue = new CircularQueue<>(10);
queue.enqueue(1);
queue.enqueue(2);
queue.enqueue(3);
queue.enqueue(4);
for (int i = 0; i < 3; i++)
{
System.out.print("Dequeue: " + queue.dequeue());
System.out.println(" Front: " + queue.getFront() + ", Rear: " + queue.getRear());
}
int data = 100;
while (!queue.isFull())
{
queue.enqueue(data++);
}
System.out.println("Capacity: " + queue.getCapacity() + ", Size: " + queue.getSize());
while (!queue.isEmpty())
{
System.out.print("Dequeue: " + queue.dequeue());
System.out.println(" Front: " + queue.getFront() + ", Rear: " + queue.getRear());
}
}
}링크드 큐
링크드 큐는 데이터, 다음 노드를 가리키는 포인터 로 구성된 노드를 통해 큐를 구현하는 것이다. 링크드리스트의 구현 방식과 유사하다. 포인터가 추가되었기 때문에 추가 연산을 하므로 순환 큐보다는 성능이 떨어지지만 가득찬다는 개념이 없이 계속 추가 가능하다는 장점이 있다.
링크드 큐 구현하기
링크드 큐의 주요 연산은 아래와 같다.
- 선언
- 생성
- 삽입
- 제거
- 공백상태
순환 큐와 달리 포화상태 확인이 없는데 이는 링크드 큐가 데이터를 계속 추가 가능하기때문에 포화 상태인지 확인할 수 없다.
링크드 큐 선언과 생성
class Node
{
private T data;
private Node nextNode;
public Node(T data) {
this.data = data;
}
public T getData() {
return data;
}
}먼저 노드 생성이다. 다음 노드의 참조가 추가되고 노드 생성시 데이터를 입력받고 nextNode는 null 상태로 시작한다.
public class LinkedQueue<T>
{
private Node front;
private Node rear;
private int count;
}순환 큐와 같이 전단(front), 후단(rear) 가 존재하고 데이터의 갯수를 표시할 count 변수도 존재한다.
링크드 큐 삽입
삽입할 때 후단에 새로운 노드를 붙이면 끝이다.
public void enqueue(T newData)
{
Node newNode = new Node(newData);
if(front == null)
{
front = newNode;
rear = newNode;
}
else
{
rear.nextNode = newNode;
rear = rear.nextNode;
}
count++;
}이때 두가지 경우를 생각해야한다.
큐가 완전히 빈값을 경우 front가 null이기 때문에 이때 추가되는 노드는 front, rear를 둘 다 갖고 있다.
이외의 경우는 후단의 nextNode를 추가되는 노드(newNode)로, 후단(Rear)을 후단의 nextNode로 설정한다.
추가된 후에는 count를 통해 갯수를 증가한다.
링크드 큐 제거
노드를 제거할 때 전단의 다음 노드를 새로운 전단으로 만들고 전단이었던 노드를 반환한다.
public Node dequeue()
{
Node frontNode = front;
if(front.nextNode == null)
{
front = null;
rear = null;
}
else
{
front = front.nextNode;
}
count--;
return frontNode;
}삽입할 때와 마찬가지로 두가지 경우가 존재하며 제거 완료시 다른 노드가 존재하지않는다면 전단, 후단 null 처리
이외는 전단을 옮겨주기만 하면 된다. 제거 후에는 count를 감소시킨다.
공백상태 확인
public boolean isEmpty()
{
return front == null;
}전단이 null란 얘기는 큐가 비어있다는 말이므로 true를 반환한다.
예제소스
public class LinkedQueueTest {
public static void main(String[] args) {
LinkedQueue<String> queue = new LinkedQueue<>();
queue.enqueue("abc");
queue.enqueue("def");
queue.enqueue("efg");
queue.enqueue("hij");
System.out.println("Queue Size : " + queue.getSize());
while(!queue.isEmpty())
{
LinkedQueue<String>.Node popped = queue.dequeue();
System.out.println("Dequeue : " + popped.getData());
}
}
}요약
이렇게 구현해봄으로써 알 수 있는 장단점으로는
장점
- 데이터가 입력된 순서대로 처리해야 할 상황에 좋다.
단점
- 스택과 마찬가지로 중간 위치에 데이터 접근하려면 모든 데이터를 꺼내면서 찾아야한다.
'CS > 자료구조' 카테고리의 다른 글
| 이진 트리(Binary Tree) 개념 및 구현 (0) | 2022.06.17 |
|---|---|
| 트리(Tree) 개념 및 구현 (0) | 2022.06.16 |
| 스택(Stack) 개념 및 구현 (0) | 2022.05.25 |
| 더블 링크드리스트(Doubly Linked List) 개념과 구현 (0) | 2022.05.20 |
| 링크드리스트(LinkedList) 개념 및 구현 (0) | 2022.05.20 |