
링크드리스트란
기본적으로 배열을 선언할 때 new int [10]으로 크기를 지정해서 선언한다. 허나 배열의 용도에 따라 계속 크기가 변할 수 있다면 결과를 예상해 크기를 선언하기엔 메모리 낭비가 발생하여 애매모호합니다. 이때 유연하게 크기를 바꿀 수 있는 자료구조를 사용해야 하는데 그중에 하나가 링크드리스트이다.
노드
링크드리스트 내의 각 요소는 노드(Node)라고 부른다. 이 노드에는 데이터를 보관하는 필드와 다음 노드와의 연결고리 역할을 하는 포인터로 이루어져 있다.
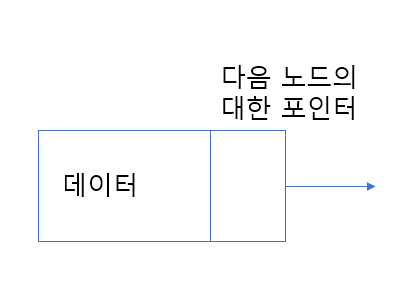
링크드리스트는 아래처럼 리스트의 첫 번째 노드인 헤드와 마지막 노드인 테일을 갖고 있다.
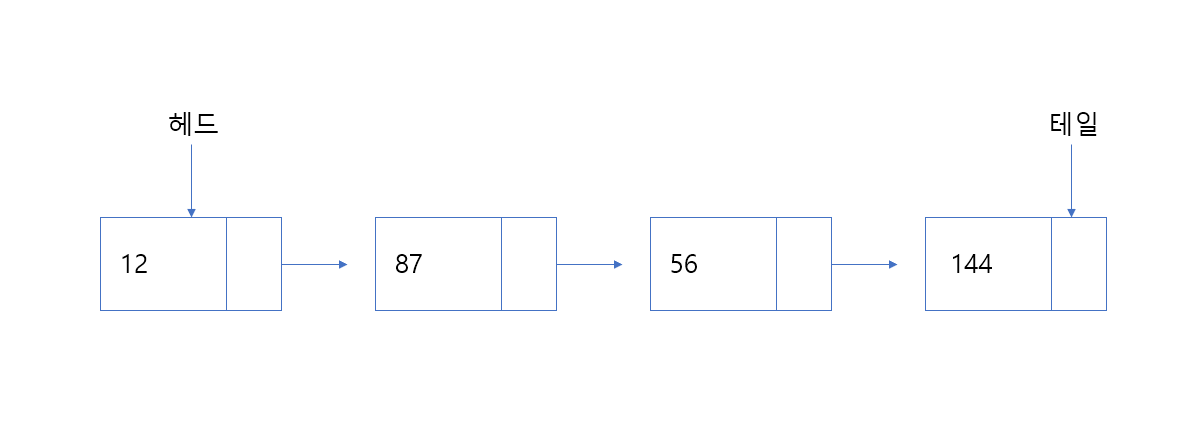
이런 구조라면 데이터의 크기를 미리 알지 못해도 된다. 데이터가 늘어날 때마다 노드를 만들어 테일에 붙이면 되기 때문이다. 리스트 사이에 노드를 삽입하거나 제거도 가능하다. 노드를 가리키는 포인터 값만 바꿔주면 된다. 허나 링크드리스트에도 단점이 있는데 이는 구현 소스를 보고 난 뒤에 설명하겠다.
아래는 자바에서의 노드 표현방식이다.
class Node
{
Object data;
Node nextNode;
public Node(Object newData)
{
this.data = newData;
this.nextNode = null;
}
}링크드리스트의 주요 연산
기본적으로 링크드리스트를 사용하기 위해 필요한 연산은 5가지이다.
- 노드 생성
- 노드 추가
- 노드 탐색
- 노드 삭제
- 노드 삽입
노드 생성
Node CreateNode(Object newData)
{
return new Node(newData);
}해당 메서드 실행 시 Node 생성자에 의해 data, nextNode 값이 초기화되며 생성된다. 즉 데이터가 있는 노드를 생성하되 아직 연결되지 않는 상태라는 것이다.
노드를 생성했다면 해당 노드를 연결해줘야 한다.
노드 추가
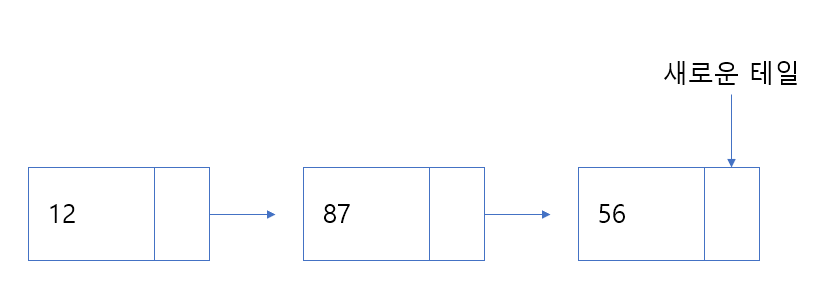
void AppendNode(Node newNode)
{
if(head == null)
{
head = newNode;
}
else
{
tail = head;
while(tail.nextNode != null)
{
tail = tail.nextNode;
}
tail.nextNode = newNode;
}
}노드가 새로 추가되었다면 두 가지의 경우가 있다
- 아무것도 없는 상태에서 추가
- 데이터가 하나라도 존재하는 상태에서 추가
첫 번째 경우는 새로 추가되는 노드가 바로 헤드이기 때문에 헤드로 설정해준다.
두 번째 경우에는 테일을 처음부터 탐색하여 끝 부분에 도달 시 테일의 다음 노드를 새로 추가되는 노드로 설정해준다.
노드 탐색
탐색 연산은 앞서 말한 링크드리스트의 단점 중의 하나이다. 일반적으로 배열은 인덱스를 통해 원하는 요소를 찾지만 링크드리스트는 헤드부터 시작해 하나하나 세며 원하는 요소를 찾는다.
Node GetNodeAt(int location)
{
Node current = head;
while(current != null && (--location) >= 0)
{
current = current.nextNode;
}
return current;
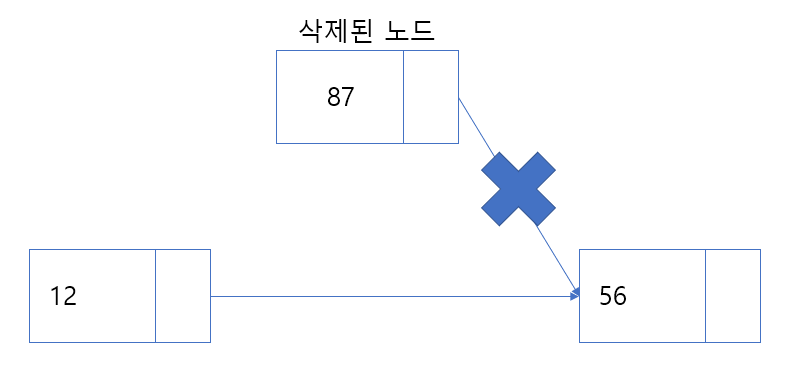
}노드 삭제
삭제 연산은 삭제하고자 하는 노드를 찾은 후 해당 노드의 다음 노드를 이전 노드의 nextNode로 연결하면 된다.
void RemoveNode(Node remove)
{
if(head == remove)
{
head = remove.nextNode;
}
else
{
Node current = head;
while(current != null && current.nextNode != remove)
{
current = current.nextNode;
}
if (current != null)
current.nextNode = remove.nextNode;
}
}노드를 삭제할 때의 경우가 2가지가 있다.
- 헤드인 노드를 제거한다면 헤드를 삭제할 노드의 nextNode로 설정해야 한다.
- 헤드부터 삭제할 노드를 탐색하여 삭제 연산을 진행한다.
삭제한 노드로 행할 행동이 없다면 그 자리에서 바로 파괴하는 것이 좋다
void DestroyNode(Node removedNode)
{
removedNode = null;
}노드 삽입
해당 연산은 노드와 노드 사이에 새로운 노드를 끼워 넣는 연산이다.
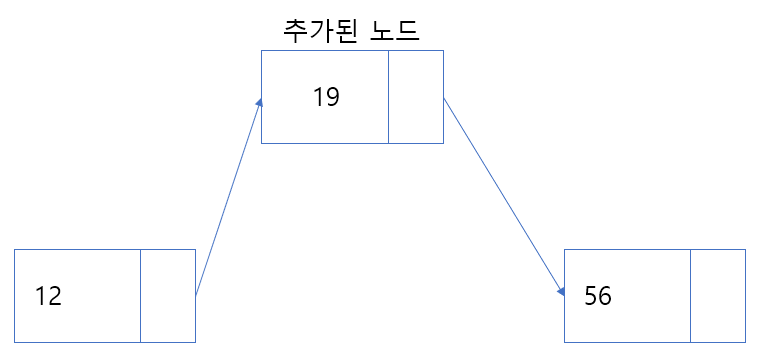
void InsertAfter(Node current, Node newNode)
{
newNode.nextNode = current.nextNode;
current.nextNode = newNode;
}추가할 노드(newNode)의 nextNode를 이전(current) 노드의 nextNode로 설정하고
이전(current)노드의 nextNode를 추가할 노드(newNode)로 설정한다.
노드 개수 세기
int GetNodeCount()
{
int count = 0;
Node current = head;
while(current != null)
{
current = current.nextNode;
count++;
}
return count;
}코드 그대로 헤드부터 끝까지 순회하며 count 한 값을 리턴한다.
요약
이렇게 직접 구현해봄으로써 링크드리스트의 장단점을 파악할 수 있다
단점
- 다음 노드를 가리키는 값이 존재하기 때문에 메모리가 배열에 비해 더 필요하다
- 특정 노드를 찾으려면 비용도 크며 속도도 느리다. 예를 들어 찾으려는 값이 리스트의 끝에 있다면 n회까지 진행해야 한다.
장점
- 새로운 노드의 추가/삽입/삭제가 쉽고 빠르다.
종합해보자면 링크드리스트를 쓰기 적절한 곳은 레코드의 추가/삽입/삭제가 잦고 조회는 드문 곳이란 걸 알 수 있다.
예를 들면 데이터베이스에서 조회해온 레코드를 순차적으로 다루는 데 적절할 것이다.
'CS > 자료구조' 카테고리의 다른 글
| 이진 트리(Binary Tree) 개념 및 구현 (0) | 2022.06.17 |
|---|---|
| 트리(Tree) 개념 및 구현 (0) | 2022.06.16 |
| 큐(Queue) 개념 및 구현 (0) | 2022.06.03 |
| 스택(Stack) 개념 및 구현 (0) | 2022.05.25 |
| 더블 링크드리스트(Doubly Linked List) 개념과 구현 (0) | 2022.05.20 |
링크드리스트란
기본적으로 배열을 선언할 때 new int [10]으로 크기를 지정해서 선언한다. 허나 배열의 용도에 따라 계속 크기가 변할 수 있다면 결과를 예상해 크기를 선언하기엔 메모리 낭비가 발생하여 애매모호합니다. 이때 유연하게 크기를 바꿀 수 있는 자료구조를 사용해야 하는데 그중에 하나가 링크드리스트이다.
노드
링크드리스트 내의 각 요소는 노드(Node)라고 부른다. 이 노드에는 데이터를 보관하는 필드와 다음 노드와의 연결고리 역할을 하는 포인터로 이루어져 있다.
링크드리스트는 아래처럼 리스트의 첫 번째 노드인 헤드와 마지막 노드인 테일을 갖고 있다.
이런 구조라면 데이터의 크기를 미리 알지 못해도 된다. 데이터가 늘어날 때마다 노드를 만들어 테일에 붙이면 되기 때문이다. 리스트 사이에 노드를 삽입하거나 제거도 가능하다. 노드를 가리키는 포인터 값만 바꿔주면 된다. 허나 링크드리스트에도 단점이 있는데 이는 구현 소스를 보고 난 뒤에 설명하겠다.
아래는 자바에서의 노드 표현방식이다.
class Node
{
Object data;
Node nextNode;
public Node(Object newData)
{
this.data = newData;
this.nextNode = null;
}
}링크드리스트의 주요 연산
기본적으로 링크드리스트를 사용하기 위해 필요한 연산은 5가지이다.
- 노드 생성
- 노드 추가
- 노드 탐색
- 노드 삭제
- 노드 삽입
노드 생성
Node CreateNode(Object newData)
{
return new Node(newData);
}해당 메서드 실행 시 Node 생성자에 의해 data, nextNode 값이 초기화되며 생성된다. 즉 데이터가 있는 노드를 생성하되 아직 연결되지 않는 상태라는 것이다.
노드를 생성했다면 해당 노드를 연결해줘야 한다.
노드 추가
void AppendNode(Node newNode)
{
if(head == null)
{
head = newNode;
}
else
{
tail = head;
while(tail.nextNode != null)
{
tail = tail.nextNode;
}
tail.nextNode = newNode;
}
}노드가 새로 추가되었다면 두 가지의 경우가 있다
- 아무것도 없는 상태에서 추가
- 데이터가 하나라도 존재하는 상태에서 추가
첫 번째 경우는 새로 추가되는 노드가 바로 헤드이기 때문에 헤드로 설정해준다.
두 번째 경우에는 테일을 처음부터 탐색하여 끝 부분에 도달 시 테일의 다음 노드를 새로 추가되는 노드로 설정해준다.
노드 탐색
탐색 연산은 앞서 말한 링크드리스트의 단점 중의 하나이다. 일반적으로 배열은 인덱스를 통해 원하는 요소를 찾지만 링크드리스트는 헤드부터 시작해 하나하나 세며 원하는 요소를 찾는다.
Node GetNodeAt(int location)
{
Node current = head;
while(current != null && (--location) >= 0)
{
current = current.nextNode;
}
return current;
}노드 삭제
삭제 연산은 삭제하고자 하는 노드를 찾은 후 해당 노드의 다음 노드를 이전 노드의 nextNode로 연결하면 된다.
void RemoveNode(Node remove)
{
if(head == remove)
{
head = remove.nextNode;
}
else
{
Node current = head;
while(current != null && current.nextNode != remove)
{
current = current.nextNode;
}
if (current != null)
current.nextNode = remove.nextNode;
}
}노드를 삭제할 때의 경우가 2가지가 있다.
- 헤드인 노드를 제거한다면 헤드를 삭제할 노드의 nextNode로 설정해야 한다.
- 헤드부터 삭제할 노드를 탐색하여 삭제 연산을 진행한다.
삭제한 노드로 행할 행동이 없다면 그 자리에서 바로 파괴하는 것이 좋다
void DestroyNode(Node removedNode)
{
removedNode = null;
}노드 삽입
해당 연산은 노드와 노드 사이에 새로운 노드를 끼워 넣는 연산이다.
void InsertAfter(Node current, Node newNode)
{
newNode.nextNode = current.nextNode;
current.nextNode = newNode;
}추가할 노드(newNode)의 nextNode를 이전(current) 노드의 nextNode로 설정하고
이전(current)노드의 nextNode를 추가할 노드(newNode)로 설정한다.
노드 개수 세기
int GetNodeCount()
{
int count = 0;
Node current = head;
while(current != null)
{
current = current.nextNode;
count++;
}
return count;
}코드 그대로 헤드부터 끝까지 순회하며 count 한 값을 리턴한다.
요약
이렇게 직접 구현해봄으로써 링크드리스트의 장단점을 파악할 수 있다
단점
- 다음 노드를 가리키는 값이 존재하기 때문에 메모리가 배열에 비해 더 필요하다
- 특정 노드를 찾으려면 비용도 크며 속도도 느리다. 예를 들어 찾으려는 값이 리스트의 끝에 있다면 n회까지 진행해야 한다.
장점
- 새로운 노드의 추가/삽입/삭제가 쉽고 빠르다.
종합해보자면 링크드리스트를 쓰기 적절한 곳은 레코드의 추가/삽입/삭제가 잦고 조회는 드문 곳이란 걸 알 수 있다.
예를 들면 데이터베이스에서 조회해온 레코드를 순차적으로 다루는 데 적절할 것이다.
'CS > 자료구조' 카테고리의 다른 글
| 이진 트리(Binary Tree) 개념 및 구현 (0) | 2022.06.17 |
|---|---|
| 트리(Tree) 개념 및 구현 (0) | 2022.06.16 |
| 큐(Queue) 개념 및 구현 (0) | 2022.06.03 |
| 스택(Stack) 개념 및 구현 (0) | 2022.05.25 |
| 더블 링크드리스트(Doubly Linked List) 개념과 구현 (0) | 2022.05.20 |